Very popular with engineers, scientists, universities, and high school students, they've been around for a while, ever since IBM installed the IBM 704 mainframe in 1954 employing a 36 bit word, and then in 1957, released the high level Fortran programming language to run on the mainframe. Called a REAL or FLOAT variable, as opposed to an INTEGER.
Defined by the IEEE in 1985 as a 32 bit or single precision floating point variable, its 8 bit "exponent" enables the number to be up to 1038 decimal digits in length. It can thus be a very large number, or a very tiny one, with up to 37 zeroes following the decimal point. However, note, beside those leading / trailing zeroes, it contains only 6~7 significant digits (known as its "mantissa").
In the 1960s IBM increased its size to what became known as a 64 bit or LONG REAL variable, now with 15~16 significant digits. It was introduced on the IBM 7094 in 1962, initially as a 62 bit number, becoming 64 bits on the System/360 Model 44 launched in 1965. Defined as Double Precision in later Fortran manuals.
In 1964 a competitor Control Data released one of the early "super computers", the CDC 6600, a 60 bit computer that used an 11 bit exponent, enabling the number to be up to 10308 decimal digits in length. However for IBM and most hardware manufacturers, the 8 bit exponent remained the norm.
The CDC 6600 cost $US6 to 10 million to purchase in 1964 currency, as opposed to $US60,000 to $360,000 for the various IBM 360 models. In terms of raw power, the CDC's CPU apparently ran at 40MHz with a benchmark of 3 million FLOPS (Floating Point Operations per second). In contrast, today, a typical laptop's CPU performs at perhaps about 100 Gigaflops (billion), and a typical GPU (graphics card) can handle 1 - 10 Teraflops (trillion).
...In April 1965 with transistor density on an integrated circuit at 50 components, and the distance between transistors at one twentieth of a millimetre, Gordon Moore at Fairchild Semiconductors said that with development causing that density to double yearly, by 1975 chip density could be at 65,000.
In 1971 his newly formed company Intel released the 4004 CPU chip that contained 2,300 components, Moore's Law it was being called. But almost immediately the acceleration halted, 10,000 was the figure in 1975, and Gordon Moore revised his expectation to being a doubling "every two years". Then it sped up again, so he reworded it to "every 18 months". In 2020 as the distance between components approaches the size of atoms, and with a transistor density of 100 million per square millimetre, yes, what comes next?
Back to 1980. A major advance utilizing the 11 bit exponent and a 53 bit mantissa was the Intel 8087 math coprocessor launched in 1980, also with a proprietary 80 bit format that was used for temporary intermediate values. The unit was made optional on IBM-compatible PCs until 1989 and the release of i486 chip, and has been integrated ever since.
Employed with
dBASE II databases in 1979, with values ranging from 1.8e+63 to 1e-63, and accuracy up to 10 digits.
Lotus 1-2-3 Spreadsheets in 1983
dBASE III Plus in 1986, and DBXL, a dBASE compatible. In Section 5.5 in the DBXL manual, it specifies numeric values may range from 1e+308 (i.e. 10308) to 1e-307 and up to 19 significant digits may be stored in a numeric field with one digit reserved for a decimal point. The maximum length of the integer portion is 16 digits, the decimal portion is 15 digits. If the number exceeds 16 digits, just 13 significant digits are retained.
Microsoft Excel in 1987 and Google Sheets in 2006
Microsoft SQL Server in 1989 and MySQL in 1995 databases. Current SQL Server databases allow for 38 significant digits
Extract from an article in stackoverflow.comWhat's the difference between a single precision (32-bit) and double precision (64-bit) floating point operation?
I read a lot of answers but none seems to correctly explain where the word double comes from. I remember a very good explanation given by a University professor I had some years ago.
A single precision floating point representation uses a word of 32 bit.
1 bit for the sign, S
8 bits for the exponent, 'E' (including its exponent bias of 127)
24 bits for the fraction, also called mantissa, or coefficient (even though just 23 are represented). Let's call it 'M' (for mantissa, I prefer this name as "fraction" can be misunderstood).
Representation:
(Just to point out, the sign bit is the last, not the first.)
A double precision floating point representation, uses a word of 64 bit.
1 bit for the sign, S
11 bits for the exponent, 'E' (including its exponent bias of 1023)
53 bits for the fraction / mantissa / coefficient (even though only 52 are represented), 'M'
Representation:
As you may notice, I wrote that the mantissa has, in both types, one bit more of information compared to its representation. In fact, the mantissa is a number represented without all its non-significative 0. For example,
0.000124 becomes 0.124 x 10-3
237.141 becomes 0.237141 x 103
Now, it's obviously true that the double of 32 is 64, but that's not where the word comes from.
The precision indicates the number of decimal digits that are correct, i.e. without any kind of representation error or approximation. In other words, it indicates how many decimal digits one can safely use.
With that said, it's easy to estimate the number of decimal digits which can be safely used:
single precision: log10(223), which is about 6~7 decimal digits, numeric range ±10-38 to 1038
noting that the original IBM mainframe in 1954 with its 36 bit word enabled the mantissa to be log10(227), which is a full 8 decimal digits
double precision: log10(252), which is about 15~16 decimal digits, numeric range ±10-308 to 10308
Click here for some notes on quadruple precision, available on mainframe hardware, also some PC software since 2000.
Provides about 34 decimal digits, numeric range ±10-4932 to 104932
Note that COBOL with its fixed point decimal core, continues to be employed on perhaps 70% of business mainframes worldwide. At its introduction in 1960 it employed 18 digit numbers. This has recently expanded to 31 digit numbers.
With fixed point decimals, financial managers appreciated the lack of need for software rounding, caused by inbuilt floating point errors such as the lack of a finite binary representation for decimal numbers such as 0.1 and 0.01, etc. Multiplying $17.10 by 5 could result in a ghastly printout such as $85.4999999999972. "Why can't it multiply without rounding issues?", managers would ask, and there seemed to be no simple explanation. ...
Extract from www.quora.com/What-is-0-1-in-binary
Steve Chastain
·
MS in Electrical and Electronics Engineering & Control Engineering, Air Force Institute of Technology (Graduated 1999)3y
Assuming you mean 0.1 as a decimal number, then the solution would be to see how many binary fractions “fit” into it.
Expressing binary fractions using decimal numbers for clarity sake,
we note 0.1 < ½,
so, 0.1 decimal starts off as 0.0… binary.
Next, 0.1 < ¼,
so 0.00… binary.
0.1 < 1/8 means 0.000… binary.
0.1 > 1/16, so we have our 1st 1 in the series: 0.0001…
which means 0/2 + 0/4 + 0/8 + 1/16 + … (again, using decimal numbers for binary fractions).
Now 1/10 - 1/16 = 0.0375 (decimal),
so we go on to 0.0375 > 1/32 (= 0.03125), so 0.1 decimal is 0.00011… binary.
0.0375 - 0.03125 = 6.25 * 10^3 < 1/64, so now we have 0.000110…
6.25 * 10^3 < 1/128, but 6.25 * 10^3 > 1/256, so now 0.1 decimal is approximately 0.00011001… binary.
Going to the nearest 1/1,024 (“1 K”th), we have 0.1 decimal as approximately 0.0001100110… binary.
Now, you just have to choose to what resolution you want to go.
NB: 0.1 is a rational number, so it’s natural to expect its binary expression to be a “terminating” or “repeated” binary fractional expression. (That “.” is now a binary point, not a decimal point! :D)** End of notes
 In 2020 as the distance between components approaches the size of atoms, and with a transistor density of 100 million per square millimetre, yes, what comes next?
In 2020 as the distance between components approaches the size of atoms, and with a transistor density of 100 million per square millimetre, yes, what comes next?  (Just to point out, the sign bit is the last, not the first.)
A double precision floating point representation, uses a word of 64 bit.
(Just to point out, the sign bit is the last, not the first.)
A double precision floating point representation, uses a word of 64 bit.
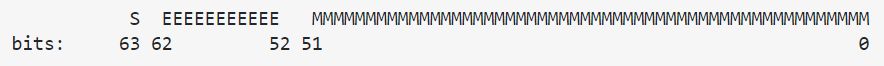 As you may notice, I wrote that the mantissa has, in both types, one bit more of information compared to its representation. In fact, the mantissa is a number represented without all its non-significative 0. For example,
As you may notice, I wrote that the mantissa has, in both types, one bit more of information compared to its representation. In fact, the mantissa is a number represented without all its non-significative 0. For example,